
Features
Simplicity
Fiber based pseudo-blocking programming model
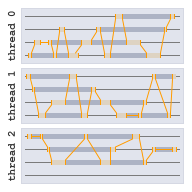
The key idea behind vibe.d was to take the fast and resource friendly asynchronous I/O model (AIO) and make it comfortable to use. Some other frameworks or toolkits such as node.js directly expose the event based interface of AIO using callback functions. While this is a workable approach, it has several drawbacks.
First and foremost, it often becomes tedious and confusing to write sequences of code (e.g. performing multiple consecutive database queries). Each step will introduce a new callback with a new scope, error callbacks often have to be handled separately. Especially the latter is a reason why it is tempting to just perform lax error handling.
Another consequence of asynchronous callbacks is that there is no meaningful call stack. Not only can this make debugging more difficult, but features such as exceptions cannot be used effectively in such an environment.
The approach of vibe.d is to use asynchronous I/O under the hood, but at the same time make it seem as if all operations were synchronous and blocking, just like ordinary I/O.
What makes this possible is D's support for so called fibers (also often called co-routines). Fibers behave a lot like threads, just that they are actually all running in the same thread. As soon as a running fiber calls a special yield() function, it returns control to the function that started the fiber. The fiber can then later be resumed at exactly the position and with the same state it had when it called yield(). This way fibers can be multiplexed together, running quasi-parallel and using each threads capacity as much as possible.
All of this usually happens behind the curtain of the vibe.d API, so that everything feels like just working with normal threads and blocking operations. All blocking functions, such as sleep() or read() will yield execution whenever they need to wait for an event and let themselves resume when the event occurs.
Using these tools, the event based nature of AIO is completely hidden from the user of the library. It also blends seamlessly with the built-in support for multi-threading. All concurrent operation are done using so called tasks. Every task runs inside of a single fiber and is multiplexed together with other tasks that run at the same time. To the user of the toolkit there is usually no visible difference between a task and a thread.
Having said all that, vibe.d can also be used without any fibers and no event loop if it has to, resembling the standard blocking I/O model.

Compact API
There is a strong focus on a short and simple API. Common tasks are kept as short and high level as possible, while still allowing fine grained control if needed. By using some of D's advanced features, typical vibe.d based programs reach a level of conciseness that usually only scripting languages such as Ruby can offer.
Zero-downtime changes
[work-in-progress] An integrated load balancer is able to dynamically compile, run and test new processes before switching them live after the code has been modified. This allows for seamless and low-risk changes on live-systems.
Exception based error handling
Usually, exception handling is restricted to local error handlers in event-based environments - it is impossible to wrap a sequence of events into a try-catch block, because every operation creates a new scope when callbacks are involved. vibe.d with its fiber based approach on the other hand has full support for exception handling.
A fiber behaves almost exactly like a thread regarding the stack; a single consistent call stack exists across all events that are handled in sequence. This way it becomes possible to naturally use exception handling, and especially in a web service environment exceptions are the ideal form of error handling.
Exceptions have the extremely useful feature that you can barely ignore them. As such, it is much more difficult to introduce subtle bugs and security holes by unintentionally ignoring error conditions. Any uncaught exceptions will automatically generate an error page and log all useful information in case of HTTP services.
Productivity
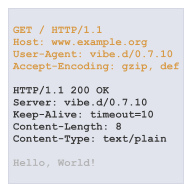
Full integrated web framework
The vibe.d library contains a complete set of tools needed for website and web service development. In addition to a HTTP 1.0/1.1 server, static file serving, an efficient template system, WebSockets, sessions and other features are already integrated. Surrounding features include a markdown filter, MongoDB and Redis drivers, cryptography, natural JSON and BSON support and a simple SMTP client.
There are also means to automatically generate JSON/REST or HTML form based interface from D classes, removing a lot of work and potential for bugs due to avoiding boilerplate code. The REST interface generator supports generation of both, the server and the client end, and as such can be used as a convenient RPC mechanism.
Native database drivers
The core library contains built-in support for MongoDB and Redis databases. These drivers provide a default for fast and flexible data storage. More database drivers are available in the DUB package registry, for example a vibe.d compatible MySQL driver.
Making existing drivers compatible is easy to do thanks to the blocking nature of vibe.d's API. The only thing that has to be done in most cases is to replace the socket calls (send(), recv(), connect() etc.) with the corresponding vibe.d functions. A blog post gives an overview of what needs to be done using the MySQL driver as an example.
Raw network and file handling
Of course, raw TCP/UDP and file access is supported by the toolkit to enable custom protocols and file formats. I/O happens through a blocking stream interface that effectively hides the fact that the underlying operations are actually event based.
Generic concurrency tools
Apart from I/O operations, all the usual tools for generic programming tasks are supported:
sleep()pauses execution of the current tasks for a specific amount of time- Timers enable asynchronous scheduling of callbacks
- Mutexes and condition variables allow for sharing data access between multiple threads without interfering with the event loop
- Support for message passing
- Data pipes for streaming data between tasks/threads
Graphical user interface integration
Contrary to most other frameworks supporting asynchronous I/O, vibe.d fully integrates with the UI event loop, so that it can be used to power applications with a graphical user interface.
For Windows, there is a native event driver implementation that makes use of the MsgWaitForMultipleObjectsEx function to process window messages together with I/O or concurrency events. For systems running X11, it's possible to use createFileDescriptorEvent to listen on the display connection instead of using XNextEvent. Finally, macOS has an event loop based on `CFRunLoop`, which processes CoreFramework events, as well as basic kqueue events.
An advanced example of this is Aspect, our photo management application that uses vibe.d for all of its I/O and concurrency needs. Tasks are a great fit for the asynchronous nature of the GUI system APIs, allowing to turn most event/callback based code into clear procedural code with a linear execution path. This results in both, more readable and more robust code. For Aspect, we are using direct Win32 API access on Windows and SDL2 on Linux and macOS.
Performance
Asynchronous I/O operations
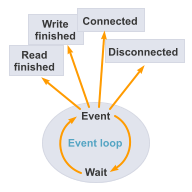
Instead of using classic blocking I/O together with multi-threading for doing parallel network and file operations, all operations are using asynchronous operating system APIs. eventcore is used to access these APIs operating system independently.
Using asynchronous I/O has several advantages, the main point being that the memory overhead is much lower. This is because only a single hardware thread is needed to handle an arbitrary number of concurrent operations. The thread typically rests waiting for events and is woken up by the operating system as soon as new data arrives, a new connection is established, or an error occurs. After each initiated blocking operation (e.g. writing data to a socket), the thread will go back to sleep and let the operating system execute the operation in the background.
Another important aspect for speed is that, because there is only one or a few threads necessary, it is often possible to save a lot of expensive thread context switches. However, note that if the application has to do a lot of computations apart from the actual I/O operations, vibe.d has full support for multi-threading to fully exploit the system's multi-core CPU.
Because using the asynchronous event based model is often more involved regarding the application implementation, fibers are used together with an event based scheduler to give the impression of classic blocking calls and multi-threading, thus hiding the additional complexities, while retaining the performance characteristics of asynchronous I/O.
Multi-threading support
While the performance is usually very good in a single-threaded application due to the use of asynchronous I/O and fibers, there are applications that can greatly benefit from using multiple cores. vibe.d supports multiple ways to exploit this additional computational power, leaving the decision for the threading architecture to the application writer.
Apart from allowing the use of low-level D threads, a thread pool is provided, which is used for any task started with runWorkerTask instead of runTask. This is mainly useful for running computationally expensive operations, such as decoding images, alongside the normal program flow, but it can also be used for better performance of I/O heavy tasks in certain cases.
The library is very flexible in the way that multi-threading can be employed and makes sure that no low-level race-conditions can occur, as long as no unsafe operations, such as cast()s or __gshared variables, are used. The following list shows some typical threading architectures:
- Distributed processing of incoming connections
- The HTTP server (as well as any other TCP based server) can be instructed to process incoming connections across the worker threads of the thread pool instead of in the main thread. For applications that don't need to share state across different connections in the process, this can increase the maximum number of requests per second linearly with the number of cores in the system. This feature is enabled using the
HTTPServerOption.distributeorTCPListenOptions.distributesettings. - Using worker tasks for computations
- Computationally expensive tasks can be off-loaded from the main thread by performing them with
runWorkerTask. Any such task will be executed in the thread pool. This approach is useful whenever an application has such computationally expensive tasks to do, because it allows pure I/O tasks to stay unaffected by heavy computational load. Probably the most common example of such a task is image processing/decoding/encoding. - Using plain D threads
- Normal D threads can also be used together with vibe.d. This is important when the threading primitives of the D standard library are used. Apart from the D core threads, these are
std.parallelismandstd.concurrency. Note however, that parts of the D standard library shouldn't be mixed with vibe.d's I/O functions, because they block the event loop. Most notably, the message passing functions instd.concurrencyare currently* not compatible with vibe.d's event loop and should be replaced with the ones invibe.core.concurrency.
Note that vibe.d also includes experimental library based support of isolated and scoped references. These allow mutable data to be passed between threads without having to use mutexes or similar means to synchronize data access. This is especially useful when transferring the data used in worker tasks between the worker thread and the main thread.
Natively compiled code

Vibe.d is written in the D Programming Language. D is a C-style language that compiles down to native machine code with minimal runtime overhead. In addition to being fast, D offers a number of features that allow additional performance improvements and especially code readability, safety and usability improvements compared to other languages such as C++.
Some notable features are listed here, but there are a lot of additional things which would be beyond the scope of this text. See theD feature pageor the Programming in D online book for a more general overview.
- Templates, mixins and compile-time functions
-
The meta-programming system in D is extremely powerful. Templates (comparable to C++ templates) support variadic parameters, as well as string and alias parameters - a feature which enables very comfortable compile-time interfaces.
The ultimate power is given by the possibility to execute ordinary functions at compile time, as well as the ability to compile a string given at compile time as D code. This functionality is similar to JavaScript's
eval()function, just that the result is statically compiled to machine code (and without the runtime security implications ofeval()).These features together with the possibility to read files at compile time have enabled the powerful Diet template parser.
- Garbage collection
-
The D runtime offers built-in garbage collection, which enables some interesting possibilities, apart from the obvious advantage of no need for manual memory management and the associated risk of memory leaks and dangerous dangling references.
Most notably, it allows to work with immutable data, such as strings or objects, which can be safely referenced and passed between threads without any synchronization overhead. When passing data between threads, it is statically enforced that the data is safe to be referenced from multiple threads. This avoids a whole class of difficult to reproduce and track down bugs common in multi-threaded code of many other languages.
- Closures and lambdas
-
A feature also known from some scripting and functional languages, but also C# and a few others are closures and lambdas. They allow to specify callback functions in a very compact and readable way. In turn they tend to have a strong influence on the API design, as they can make computationally efficient or safe APIs actually bearable (or even pleasant) to use.
- Properties
-
Properties are functions that look like they were a field of a class or struct. They are used throughout the API to get a logical and intuitive interface without all clamps and additional typing needed for normal function calls.
- Module system
-
D's module system is similar to the one used in Java. Among other things it encodes the dependencies between different modules (D files) in a semantically clear way. Using this information, it becomes possible to build whole applications just by specifying the root file (app.d) on the command line. The dependencies can be found recursively. The rdmd build tool included with the D compiler, which is supported by the DUB package manager, works this way.
- Arrays and slices
-
Arrays support native slicing with a very natural syntax. Together with the garbage collector they enable extremely fast string parser implementations which are safe (bounds checking) and easy to read at the same time.
- Concise and readable syntax
-
The syntax in general is very clean and to the point - especially compared to its perhaps closest relative, C++. But it doesn't need to fear modern scripting languages such as Ruby and Python in this regard either. Apart from the occasional need to specify an explicit type (types can be inferred using
auto), you will discover that there is not much to miss and that development using D is highly efficient.
Compile-time "Diet" templates

vibe.d has built-in support for Diet HTML templates based on the Pug template syntax known from node.js which in turn is based on Haml. These templates remove all the syntax overhead that is inherent to HTML's tag based notation and also allow the inline specification of dynamic elements. Typically, these elements are written in a dynamic scripting language (JavaScript in case of Pug).
In vibe.d, however, templates can contain embedded D code. The templates are read and parsed while the application is being compiled and optimized D code is generated for them. This means that the runtime overhead for those templates is non-existent - there are no disk accesses, no parsing and there is no string copying involved because all of this has already been done before the application has even started.
At the same time you can program in the same language as for the rest of the application, which makes for a very consistent development experience.